News / Data Updates
- July 2026: The cumulative dataset for the Cooperative Election Study (CES) is updated with 2025 data and minor fixes, V12
- February 2026: The general election candidate dataset (CAGE) is updated to include 2024 results, V4
- June 2025: I launched the The Ticket Splitting Visualizer, a first-of-its-kind interactive platform developed to compare ticket splitting across hundreds of pairs of contests, with real ballots: ballots.isps.yale.edu
Recent Papers
- The Role of Confounders and Linearity in Ecological Inference: A Reassessment (with Cory McCartan). Working Paper, Revised and Resubmitted
- Identification and Semiparametric Estimation of Conditional Means from Aggregate Data (with Cory McCartan). Working Paper, Under Review
- Collective Representation in Congress (with Stephen Ansolabehere). Perspectives on Politics, vol. 24, Special Issue 1, pp. 269-288. 2026. [Data] [ISPS blog]
- How Partisan are U.S. Local Elections? Evidence from 2020 Cast Vote Records. (with Aleksandra Conevska, Shigeo Hirano, Can Mutlu, Jeffrey B. Lewis, and James M. Snyder, Jr.). American Political Science Review, vol. 120, no. 2, pp. 564-581. 2026. [Related Publication: CVR Data], [Interactive Tool: ballots.isps.yale.edu] [Replication Data]
- Representation in America: Majority Rule in a Divided Political System (with Stephen Ansolabehere). Book Manuscript, University of Chicago Press. Publication February 2027.
Abstract
Estimating conditional means using only the marginal means available from aggregate data is known as the ecological inference problem. We reassess this literature, arguing that it has understudied two issues: how practitioners should control for confounding, and how methodologists can leverage the linearity inherent in the structure of the problem. On the former, we formalize ignorability conditions like those in causal inference and outline consistent plug-in estimators: These are credible when covariates make the ignorability condition plausible. On the latter, we show that aggregation restricts the target function to be partially linear. Such linearity clarifies the connections between King's (1997) methodology, its predecessors, and subsequent developments. That motivates a recent doubly-robust technique that enters covariates flexibly while leveraging linearity. Finally, we test these methods in datasets where the ground truth is fortuitously observed. In these common applications, all methods tested were prone to overestimating racial polarization and underestimating split-ticket voting.
Abstract
We introduce a new method for estimating the mean of an outcome variable within groups when researchers only observe the average of the outcome and group indicators across a set of aggregation units, such as geographical areas. Existing methods for this problem, also known as ecological inference, implicitly make strong assumptions about the aggregation process. We first formalize weaker conditions for identification, which motivates estimators that can efficiently control for many covariates. We propose a debiased machine learning estimator that is based on nuisance functions restricted to a partially linear form. Our estimator also admits a semiparametric sensitivity analysis for violations of the key identifying assumption, as well as asymptotically valid confidence intervals for local, unit-level estimates under additional assumptions. Simulations and validation on real-world data where ground truth is available demonstrate the advantages of our approach over existing methods. Open-source software is available which implements the proposed methods.Abstract
The aspiration of representative democracy is that the legislature will make decisions that reflect what the majority of people want. The U.S. Constitution, however, created a Congress with both majoritarian and counter-majoritarian forces. We study public opinion on 103 important issues on the congressional agenda from 2006 to 2022 using the Cooperative Congressional Election Study. Congress made decisions that aligned with what the majority wanted on 55 percent of these issues. Analysis of each issue further reveals the circumstances when Congress represents the majority and the many ways that representation fails. The likelihood that the House passes a bill is usually a reflection of public support for that policy, but the ultimate fate of bills depends on partisan control of the two chambers of Congress and the degree of divisiveness (or polarization) between the two party bases in the public. Legislative institutions make it difficult to pass popular issues, but even more difficult to pass unpopular ones. As a result, most representational failure occurs because Congress fails to pass a popular bill, rather than because Congress passes a bill that the public did not want.Abstract
Analyzing nominally partisan contests, previous literature has argued that state and local politics have nationalized. Here we use individual ballots from the 2020 general elections covering over 43 million voters to study the relationship between individual national partisanship and voting in over 4500 down-ballot contests, including nonpartisan races and ballot measures. Voting in partisan contests can be explained by voter’s national partisanship, consistent with existing literature. However, we find that voting for local nonpartisan offices (n = 1484 contests) and ballot measures (n = 1576) is much less partisan. National partisanship explains more than 80 percent of the within-contest variation in voting for partisan state and local offices but less than 10 percent for local spending-related ballot measures. Voting for spending on roads and water are less partisan than those on education and housing, and these votes are more correlated with each other than with national partisanship.Work in Progress
- Political Engagement and the Swing Vote
- Legislator Explanations of Tough Votes and Copartisan Response
- Modeling Complex Contingency Tables
Peer-Reviewed Publications
American Politics
- Ticket Splitting in a Nationalized Era. The Journal of Politics, vol.88 (1), p.47-62. 2026. [Preprint] [Replication Data] [Covered by The Post and Courier, Governing, Colorado Public Radio News].
- Cast Vote Records: A Database of Ballots from the 2020 U.S. Election (with Mason Reece, and 12 others; co-first author with Reece). 2024. [Dataset] [Preprint] [ISPS blog] Nature Scientific Data
- The Geography of Racially Polarized Voting: Calibrating Surveys at the District Level. (with Stephen Ansolabehere, Angelo Dagonel, and Soichiro Yamauchi). American Political Science Review, vol. 118, p. 922-939. 2024. [Open Access at APSR, preprint with appendix and all estimates] [ISPS blog, WSHU radio] [Replication, Data Release] [Software: ccesMRPprep, ccesMRPrun, synthjoint] [WISM slides]
- Widespread Partisan Gerrymandering Mostly Cancels Nationally, but Reduces Electoral Competition [ISPS blog] (with Christopher Kenny, Cory McCartan, Tyler Simko, and Kosuke Imai). Proceedings of the National Academy of Sciences (PNAS), vol. 120 (25), e2217322120. 2023.
- Congressional Representation: Accountability from the Constituent’s Perspective. (with Stephen Ansolabehere). American Journal of Political Science. 2022. [Summarized in the AJPS Blog] [Data] [Preprint with full appendix]
- Wealth, Slave Ownership, and Fighting for the Confederacy: An Empirical Study of the American Civil War. (with Andrew B. Hall and Connor Huff). American Political Science Review, vol. 113, p. 658-673. 2019. [Covered by The Weeds podcast] [Data]
- [Dissertation] The Swing Voter Paradox: Electoral Politics in a Nationalized Era. Ph.D. Dissertation, Harvard University.
Abstract
Party loyalty in U.S. Congressional elections has reached heights unprecedented in the post-war era. Theories of partisanship as informational cues would predict that ticket splitting from national partisanship should be even more rare in low-information elections. Yet, here I show that ticket splitting in state and local offices is often higher than in Congress. I use cast vote records from voting machines that overcome ecological inference challenges, and develop a clustering algorithm to summarize such ballot data. For example, about a third of South Carolina Trump voters form a bloc whose probability of ticket splitting is 5 percent for Congress, but 32 percent for county council and 50 percent for sheriff. I show that a model with candidate quality differentials can explain these patterns: Even in a nationalized era, some voters cross party lines to vote for the more experienced and higher quality candidate in state and local elections.Abstract
Ballots are the basis of the electoral process. A growing group of political scientists, election administrators, and computer scientists have requested electronic records of actual ballots cast (cast vote records) from election officials, with the hope of affirming the legitimacy of elections and countering misinformation about ballot fraud. However, the administration of election data in the U.S. is scattered across local jurisdictions. Here we introduce a database of cast vote records from the 2020 U.S. general election. We downloaded, standardized, and extensively checked the accuracy of a set of cast vote records collected from the 2020 election. Our initial release includes six offices – President, Governor, U.S. Senate and House, and state upper and lower chambers – covering 40.9 million voters in 20 states who voted for a total of thousands of candidates, including 2,121 Democratic and Republican candidates. This database serves as an unparalleled source of data for studying voting behavior and election administration.Abstract
Debates over racial voting, and over policies to combat vote dilution, turn on the extent to which groups' voting preferences differ and vary across geography. We present the first study of racial voting patterns in every congressional district in the US. Using large-sample surveys combined with aggregate demographic and election data, we find that national-level differences across racial groups explain 60 percent of the variation in district-level voting patterns, while geography explains 30 percent. Black voters consistently choose Democratic candidates across districts, while Hispanic and White voters’ preferences vary considerably across geography. Districts with the highest racial polarization are concentrated in the parts of the South and Midwest. Importantly, multi-racial coalitions have become the norm: in most congressional districts, the winning majority requires support from minority voters. In arriving at these conclusions, we make methodological innovations that improve the precision and accuracy when modeling sparse survey data.Abstract
Redistricting plans in legislatures determine how voters' preferences are translated into representative's seats. Political parties may manipulate the redistricting process to gain additional seats and insulate incumbents from electoral competition, a process known as gerrymandering. But detecting gerrymandering is difficult without a representative set of alternative plans that comply with the same geographic and legal constraints. Harnessing recent algorithmic advances in sampling, we study such a collection of alternative redistricting plans that can serve as a non-partisan baseline. This methodological approach can distinguish electoral bias due to partisan effects from electoral bias due to other factors. We find that Democrats are structurally and geographically disadvantaged in House elections by 8 seats, while partisan gerrymandering disadvantages them by 2 seats.Abstract
The premise that constituents hold representatives accountable for their legislative decisions undergirds political theories of democracy and legal theories of statutory interpretation. But studies of this at the individual level are rare, examine only a handful of issues, and arrive at mixed results. We provide an extensive assessment of issue accountability at the individual level. We trace the congressional rollcall votes on 44 bills across seven Congresses (2006-2018), and link them to constituent's perceptions of their representative's votes and their evaluation of their representative. Correlational, instrumental variables, and experimental approaches all show that constituents hold representatives accountable. A one-standard deviation increase in a constituent's perceived issue agreement with their representative can improve net approval by 35 percentage points. Congressional districts, however, are heterogeneous. Consequently, the effect of issue agreement on vote is much smaller at the district-level, resolving an apparent discrepancy between micro and macro studies.Abstract
How did personal wealth and slaveownership affect the likelihood Southerners fought for the Confederate Army in the American Civil War? On the one hand, wealthy Southerners had incentives to free-ride on poorer Southerners and avoid fighting; on the other hand, wealthy Southerners were disproportionately slaveowners, and thus had more at stake in the outcome of the war. We assemble a dataset on roughly 3.9 million free citizens in the Confederacy and show that slaveowners were more likely to fight than non-slaveowners. We then exploit a randomized land lottery held in 1832 in Georgia. Households of lottery winners owned more slaves in 1850 and were more likely to have sons who fought in the Confederate Army. We conclude that slaveownership, in contrast to some other kinds of wealth, compelled Southerners to fight despite free-rider incentives because it raised their stakes in the war’s outcome.Comparative Politics
- Winning Elections with Unpopular Policies: Valence Advantage and Single-Party Dominance in Japan. (with Yusaku Horiuchi and Daniel M. Smith). Quarterly Journal of Political Science, vol. 20 (4), p. 439-476. 2025. [Earlier versions coauthored with Shusei Eshima.] [Honorable mention for the 2024 Elections, Public Opinion, and Voting Behavior (EPOVB) best paper award] [Discussed in UChicago's Not Another Politics Podcast] [Replication Data].[Preprint with appendix]
Abstract
Do voters support dominant parties in democracies because of policy preferences or non-policy (valence) factors? We consider the preeminent case of Japan's Liberal Democratic Party (LDP), and investigate whether policy preferences or valence can better explain voting behavior in three recent elections (2017, 2021, 2024). We first introduce a new measurement strategy to infer individuals' utility for parties' policy platforms from conjoint experiments. Using this measure, we find that policy preferences positively correlate with vote intentions, but are not sufficient to explain LDP dominance. Many LDP voters in each election actually preferred the opposition's policies. Moreover, the LDP lost support in 2024 despite proposing a more popular set of policies. To understand what accounts for this disconnect, we experimentally manipulate party labels and decompose their effect, revealing that trust appears to be an important non-policy variable behind LDP support. We interpret these findings as evidence that much of the LDP’s support should be attributed to its valence advantage over the opposition, rather than voters' preferences for its policies.Survey Statistics, Demography, and Election Administration
- Privacy Violations in Election Results. (with Jeffrey B. Lewis and Michael Morse). Science Advances (March 2025). Formerly titled The Still Secret Ballot: The Limited Privacy Cost of Transparent Election Results. [Featured in ISPS, Bipartisan Policy Center Memo, Votebeat Texas, Votebeat Arizona]
- Evaluating Bias and Noise Induced by the U.S. Census Bureau's Privacy Protection Methods (with Christopher T. Kenny, Cory McCartan, Tyler Simko, and Kosuke Imai). Science Advances, vol. 10 (18), eadl2524. 2024. [Data]
- Comment: The Essential Role of Policy Evaluation for the 2020 Census Disclosure Avoidance System (with Christopher T. Kenny, Cory McCartan, Evan T. R. Rosenman, Tyler Simko, Kosuke Imai). Harvard Data Science Review, Jan 2023. [HDSR DOI]
- Simulated redistricting plans for the analysis and evaluation of redistricting in the United States (with Cory McCartan, Christopher Kenny, Tyler Simko, George Garcia III, Kevin Wang, Melissa Wu, and Kosuke Imai). Scientific Data, 9, 689. 2022. [Website] [Dataverse]
- Unrepresentative Big Surveys Significantly Overestimated US Vaccine Uptake. (with Valerie C. Bradley, Michael Isakov, Dino Sejdinovic, Xiao-Li Meng, and Seth Flaxman; co-first author with Bradley). Nature, vol. 600, p. 695-700. 2021. [Covered by Harvard Gazette] [Data]
- The Use of Differential Privacy for Census Data and its Impact on Redistricting: The Case of the 2020 U.S. Census. (with Chris Kenny, Cory McCartan, Evan Rosenman, Tyler Simko, and Kosuke Imai). Science Advances, vol. 7, eabk3283. 2021. Originally a Public Comment to the Census Bureau (May 28, 2021). [FAQ, Reaction to the Bureau's Response (June 9, 2021).] [Data]
- Towards Principled Unskewing: Viewing 2020 Election Polls Through a Corrective Lens from 2016. (with Michael Isakov). Harvard Data Science Review, vol. 2.4 (pre - 2020 election issue). 2020. [Covered by The Harvard Crimson] [PDF version with post-election review] [Data]
Abstract
After an election, should election officials release a copy of each anonymous ballot? Some policymakers have championed public disclosure to counter distrust, but others worry that it might undermine ballot secrecy. We introduce the term vote revelation to refer to the linkage of a vote on an anonymous ballot to the voter's name in the public voter file, and detail how such revelation could theoretically occur. Using the 2020 election in Maricopa County, Arizona, as a case study, we show that the release of individual ballot records would lead to no revelation of any vote choice for 99.83% of voters as compared to 99.95% under Maricopa's current practice of reporting aggregate results by precinct and method of voting. Further, revelation is overwhelmingly concentrated among the few voters who cast provisional ballots or federal-only ballots. We discuss the potential benefits of transparency, compare remedies to reduce privacy violations, and highlight the privacy-transparency tradeoff inherent in all election reporting.Abstract
The United States Census Bureau faces a difficult trade-off between the accuracy of Census statistics and the protection of individual information. We conduct the first independent evaluation of bias and noise induced by the Bureau's two main disclosure avoidance systems: the TopDown algorithm employed for the 2020 Census and the swapping algorithm implemented for the three previous Censuses. Our evaluation leverages the Noisy Measure File (NMF) as well as two independent runs of the TopDown algorithm applied to the 2010 decennial Census. We find that the NMF contains too much noise to be directly useful, especially for Hispanic and multiracial populations. TopDown's post-processing dramatically reduces the NMF noise and produces data whose accuracy is similar to that of swapping. While the estimated errors for both TopDown and swapping algorithms are generally no greater than other sources of Census error, they can be relatively substantial for geographies with small total populations.Abstract
In "Differential Perspectives: Epistemic Disconnects Surrounding the US Census Bureau's Use of Differential Privacy," boyd and Sarathy argue that empirical evaluations of the Census Disclosure Avoidance System (DAS), including our published analysis, failed to recognize how the benchmark data against which the 2020 DAS was evaluated is never a ground truth of population counts. In this commentary, we explain why policy evaluation, which was the main goal of our analysis, is still meaningful without access to a perfect ground truth. We also point out that our evaluation leveraged features specific to the decennial Census and redistricting data, such as block-level population invariance under swapping and voter file racial identification, better approximating a comparison with the ground truth. Lastly, we show that accurate statistical predictions of individual race based on the Bayesian Improved Surname Geocoding, while not a violation of differential privacy, substantially increases the disclosure risk of private information the Census Bureau sought to protect. We conclude by arguing that policy makers must confront a key trade-off between data utility and privacy protection, and an epistemic disconnect alone is insufficient to explain disagreements between policy choices.Abstract
This article introduces the 50stateSimulations, a collection of simulated congressional districting plans and underlying code developed by the Algorithm-Assisted Redistricting Methodology (ALARM) Project. The 50stateSimulations allow for the evaluation of enacted and other congressional redistricting plans in the United States. While the use of redistricting simulation algorithms has become standard in academic research and court cases, any simulation analysis requires non-trivial efforts to combine multiple data sets, identify state-specific redistricting criteria, implement complex simulation algorithms, and summarize and visualize simulation outputs. We have developed a complete workflow that facilitates this entire process of simulation-based redistricting analysis for the congressional districts of all 50 states. The resulting 50stateSimulations include ensembles of simulated 2020 congressional redistricting plans and necessary replication data. We also provide the underlying code, which serves as a template for customized analyses. All data and code are free and publicly available. This article details the design, creation, and validation of the data.Abstract
Surveys are a crucial tool for understanding public opinion and behaviour, and their accuracy depends on maintaining statistical representativeness of their target populations by minimizing biases from all sources. Increasing data size shrinks confidence intervals but magnifies the effect of survey bias: an instance of the Big Data Paradox. Here we demonstrate this paradox in estimates of first-dose COVID-19 vaccine uptake in US adults from 9 January to 19 May 2021 from two large surveys: Delphi–Facebook (about 250,000 responses per week) and Census Household Pulse (about 75,000 every two weeks). In May 2021, Delphi–Facebook overestimated uptake by 17 percentage points (14–20 percentage points with 5% benchmark imprecision) and Census Household Pulse by 14 (11–17 percentage points with 5% benchmark imprecision), compared to a retroactively updated benchmark the Centers for Disease Control and Prevention published on 26 May 2021. Moreover, their large sample sizes led to miniscule margins of error on the incorrect estimates. By contrast, an Axios–Ipsos online panel with about 1,000 responses per week following survey research best practices provided reliable estimates and uncertainty quantification. We decompose observed error using a recent analytic framework to explain the inaccuracy in the three surveys. We then analyse the implications for vaccine hesitancy and willingness. We show how a survey of 250,000 respondents can produce an estimate of the population mean that is no more accurate than an estimate from a simple random sample of size 10. Our central message is that data quality matters more than data quantity, and that compensating the former with the latter is a mathematically provable losing proposition.Abstract
Census statistics play a key role in public policy decisions and social science research. Yet given the risk of revealing individual information, many statistical agencies are considering disclosure control methods based on differential privacy, which add noise to tabulated data. Unlike other applications of differential privacy, however, census statistics must be post-processed after noise injection to be usable. We study the impact of the US Census Bureau's new Disclosure Avoidance System (DAS) on a major application of census statistics: the redrawing of electoral districts. We find that the DAS systematically undercounts the population in mixed-race and mixed-partisan precincts, yielding unpredictable racial and partisan biases. The DAS also leads to a likely violation of "One Person, One Vote" standard as currently interpreted, but does not prevent accurate predictions of an individual's race and ethnicity. Our findings underscore the difficulty of balancing accuracy and respondent privacy in the Census.Selected Press Coverage
Covered by AP News, Washington Post, The Harvard Crimson, San Francisco Chronicle, Matthew Yglesias blog, Statistical Modeling (Andrew Gelman's blog) by Jessica Hullman (Part 1, Part 2)Abstract
We apply the concept of the data defect index (Meng, 2018) to study the potential impact of systematic errors on the 2020 pre-election polls in twelve Presidential battleground states. We investigate the impact under the hypothetical scenarios that (1) the magnitude of the underlying non-responses bias correlated with supporting Donald Trump is similar to that of the 2016 polls, (2) the pollsters' ability to correct systematic errors via weighting has not improved significantly, and (3) turnout levels remain similar as 2016. Because survey weights are crucial for our investigations but are often not released, we adopt two approximate methods under different modeling assumptions. Under these scenarios, which may be far from reality, our models shift Trump's estimated two-party voteshare by a percentage point in his favor in the median battleground state, and increases twofold the uncertainty around the voteshare estimate.Education in Political Science
- The "Math Prefresher" and The Collective Future of Political Science Graduate Training. (with Gary King and Yon Soo Park). PS: Political Science and Politics, vol. 54, p. 537-541. 2020.
Abstract
The political science math prefresher arose a quarter-century ago and has now spread to many of our discipline’s PhD programs. Incoming students arrive for graduate school a few weeks early for ungraded instruction in math, statistics, and computer science as they relate to political science. The prefresher’s benefits, however, go beyond its technical content: it opens pathways to mastering methods necessary for political science research, facilitates connections among peers, and — perhaps most important — eases the transition to the increasingly collaborative nature of graduate work. The prefresher also shows how faculty across a highly diverse discipline have worked together to train the next generation. We review this program and advance its collaborative aspects by building infrastructure to share teaching content across universities so that separate programs can build on one another’s work and improve all of our programs.Book Manuscript: Representation in America
In Press, The University of Chicago Press. Expected Publication February 2027
(with Stephen Ansolabehere)
Representation in America: Majority Rule in a Divided Political System presents a comprehensive and data-driven look at how Congress has represented the American public, drawing on sixteen years of the Cooperative Congressional Election Study — spanning the presidencies of George W. Bush through Joe Biden — and more than 100 key legislative proposals. The result is a balanced and nuanced account of how electoral and legislative institutions channel and amplify majority preferences while tempering the most divisive proposals. We trace each stage of the representation process, from agenda setting and public opinion to individual legislator behavior, district structure, and collective congressional action. At each step they find a strong majoritarian tendency: most issues on the legislative agenda enjoy the support of the majority of Americans; voters tend to choose legislators whose policies they agree with; most legislators voted in-line with the majority of their constituencies most of the time; legislative districts magnify rather than mute majority opinion. When majority rule falls short, it is usually because popular legislation stalls—particularly in the Senate, where supermajority rules create high barriers to passage—rather than because Congress imposes laws the public opposes. Congress often fails to act when the public supports action, but it rarely acts in the absence of public support. Consequently, 80 percent of laws passed enjoyed the support of the majority of the nation.
Teaching
I received the university-wide Poorvu Award (2025) for Innovative teaching for my undergraduate teaching at Yale. Before coming to Yale, I received the Dean's award for excellence in student teaching as a teaching fellow at the Harvard Kennedy School. Below are the classes I've taught and frequently used resources.
- PLSC 277/2207: The U.S. Congress (Undergraduate. Fall 2022, Spring 2024) [Public Syllabus, 2022 version]
- PLSC 8000: Introduction to American Politics (PhD Field Seminar, Fall 2025) [Public Syllabus]
- PLSC 438/536/4507/5360: Applied Quantitative Research Design (MA, Undergraduate, and Ph.D. Fall 2022, Fall 2023, Fall 2025) [Public Syllabus]
- PLSC 862: American Elections with Comparative Perspective (Spring 2023) [Syllabus]
- Advice for Students on Writing, Visualization, and Coding: A short list of my favorite advice I frequently recommend to my students when they write papers or prepare slides.
- Teaching Resources for R and Data Science: See here for a collection of resources for teaching data science in the social sciences I have accumulated over the years.
Course Description
The United States Congress is arguably the most powerful legislature in the world. Its actions—and inaction—affect taxes, healthcare, business, the environment, and international politics. To understand the nature of legislative power in Congress and in democracies more broadly, we ask: How do successful politicians become powerful? How do they navigate rules and institutions to their advantage? What is the proper role of the lawmaking in regulating private business? Should we limit legislative lobbying and put a cap on campaign contributions? Class discussions use case studies including the Civil Rights movement in the 1960s, the Tax Reform Act under Reagan, and the Affordable Care Act under Obama. Exercises include coding and data analysis. The goal is to equip students with a broad understanding of the principles of politics, economics, public policy, and data science.
Course Description
This course is an introduction to American politics for students pursuing graduate work in political science. It surveys current research paired with several classics. Topics and approaches given consideration include institutional design, historical political development, mass attitudes, ideology, econometrics of elections, rational actors, urban politics, interest groups, and political economy. This class, PLSC 8100 (behavior, fall), and PLSC 8030 (institutions, spring) form the sequence that Ph.D. students are recommended to take for the examination in American politics.
Course Description
Research designs are strategies to obtain empirical answers to theoretical questions. Research designs using quantitative data for social science questions are more important than ever. This class, intended for advanced students interested in social science research, trains students with best practices for designing and implementing rigorous quantitative research. We cover designs in causal inference, prediction, and missing data at a high level. This is a hands-on, application-oriented class. Exercises involve programming and statistics in addition to the social sciences (politics, economics, and policy). The final project advances a research question chosen in consultation with the instructor.
Prerequisite: Any statistics or data science course that teaches ordinary least squares regression. Past or concurrent experience with a programming language such as R is strongly recommended.
Course Description
This graduate-level seminar covers foundational work on electoral politics in the United States, with some comparisons with other countries' systems and domestic proposals for reform. Readings examine work on elite position-taking, re-election, federalism, representation, and electoral systems. Accompanying readings include similar and more recent articles in comparative politics, political economy, or election law. This course has two intended audiences: students in American Politics, and students outside American Politics interested in theories of electoral democracy developed in the American Politics subfield that have then been exported to other subfields. Class emphasizes empirical research designs and analysis of available datasets in addition to reading.
Datasets
- The Cast Vote Records project is assembling ballot records for political science and election administration. Any one can interact with the Ticket Splitting Visualizer website to see how ballots reveal voting patterns in all levels of elections in ways that surveys or precinct results cannot. My JOP article on ticket splitting in a nationalized era studies nominally partisan contests, our APSR article on local elections focuses on local nonpartisan contests and ballot measures, and our Nature Scientific Data article releases a standardized database in Dataverse.
- The Cumulative CCES Common Content (2006-2024) (downloaded on Dataverse over 28,000 times) is a part of the Cooperative Congressional Election Survey Dataverse. It combines all common content respondents of the CCES and harmonizes key variables, so that researchers can analyze all years of the CCES or merge in standardized variables with their own CCES datasets.
- The Candidates in American General Elections dataset (with Jeremiah Cha and James M. Snyder, Jr.) is a comprehensive list of winning and losing candidates in U.S. Congressional, Presidential, and Gubernatorial elections. Unlike official records or other datasets, we standardize candidate names across time and office, and record the incumbency of the candidates.
- The Fifty States Redistricting Simulations project provides an ensemble of alternative maps for congressional districts that are simulated from state of the art redistricting software. These maps can be used to evaluate whether a proposed map is an outlier on any dimension. (as part of the ALARM team, with Cory McCartan, Christopher Kenny, Tyler Simko, George Garcia III, Kevin Wang, Melissa Wu, and Kosuke Imai)
- Portable Routines for Preparing CCES and ACS data for MRP (ccesMRPprep) is a set of datasets and API interfaces to facilitate Multilevel Regression Poststratification (MRP), a survey weighting method for small area estimation. Other articles already provide helpful tutorials and code for MRP. But implementing a MRP entails considerable upfront costs related to data collection, cleaning, and standardization. This package provides these routines: not only modeling software, but code to import and standardize publicly available data sources, combined with detailed documentation about these data sources.
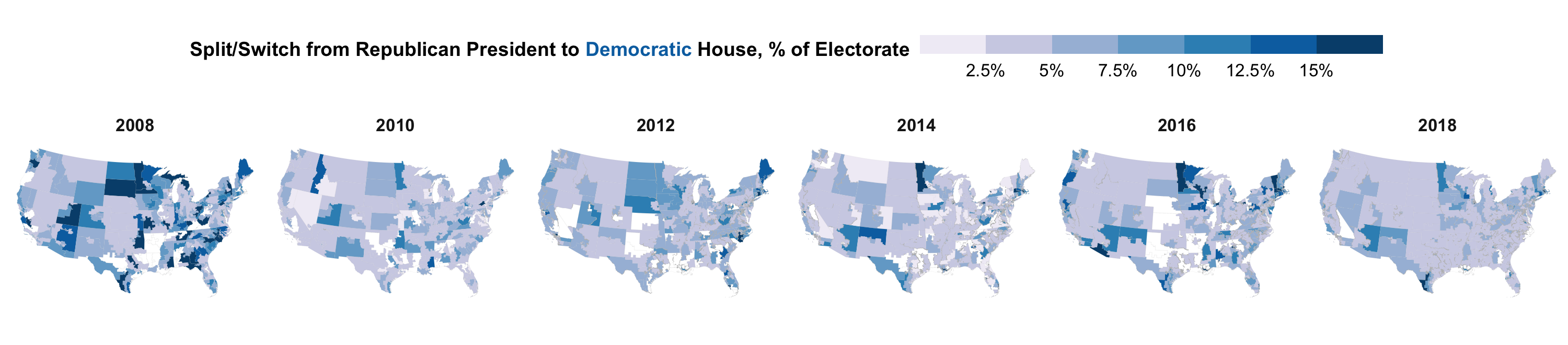
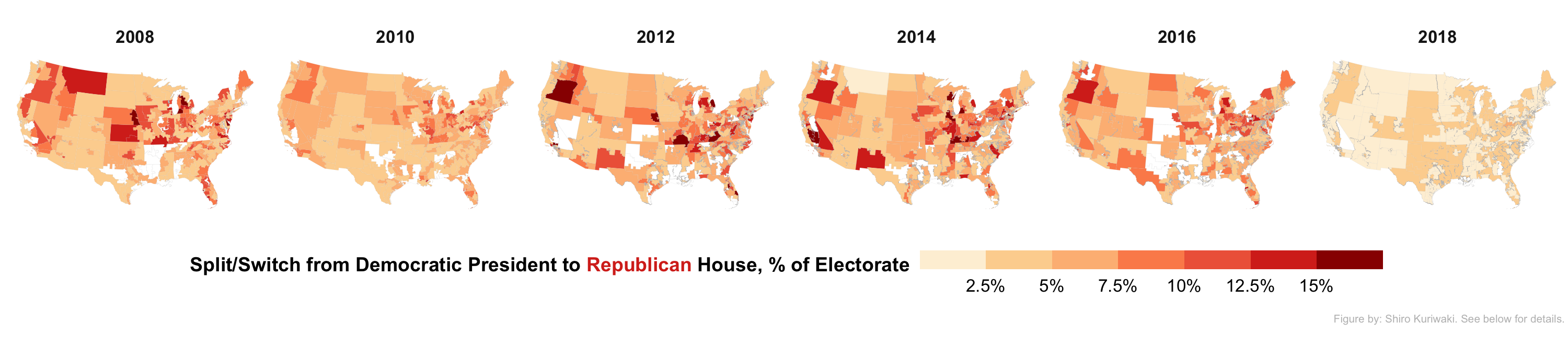
About the banner image: Survey data from the Cumulative CCES, limited to validated voters in contested districts who voted for a major party in the Presidency and House. Estimates are made at the congressional district level and use Multilevel Regression Poststratification (MRP) stratifying on age, gender, education from the ACS and using House candidate incumbency status and presidential voteshare as district-level predictors. In presidential years the values represent ticket splitting (e.g. Trump voters who voted for a 2016 Democratic House candidate); in midterm years they represent party switch from the previous presidential election (e.g. Trump voters who voted for a 2018 Democratic House candidate). Districts where a Democrat and Republican candidate did not contest the general election are left blank. Figure created by Shiro Kuriwaki.
About this website: This website uses code from Minimal Mistakes, Github Pages, uses some CSS from Matt Blackwell's website at the time, and is inspired by Sirus Bouchat's website, Andrew Hall's website, and Hanno Hilbig's website.